|
Harsh Sutaria I'm a Machine Learning Research Intern at Causal Labs and a Computer Science graduate from NYU. Previously, I was a Graduate Researcher under Prof. Yann LeCun at CILVR Lab, researching Hierarchical Planning with Latent World Models. I also worked on collision-aware navigation using Depth Barrier Regularization at AI4CE Lab under Prof. Chen Feng. Active open-source contributor to MLX, Apple's ML framework for Apple silicon. |

|
ResearchMy research focuses on Representation Learning, World Modeling, and Planning using state-of-the-art deep learning techniques. Current work includes Planning with Latent Dynamics Models, Hierarchical JEPA architectures, collision-aware navigation with Depth Barrier Regularization, and multi-modal AI systems. Tech stack: PyTorch, TensorFlow, Computer Vision (YOLO, DINOv2, VLAD-BuFF), Diffusion Models, ROS. |
|
Hierarchical Planning with Latent World Models
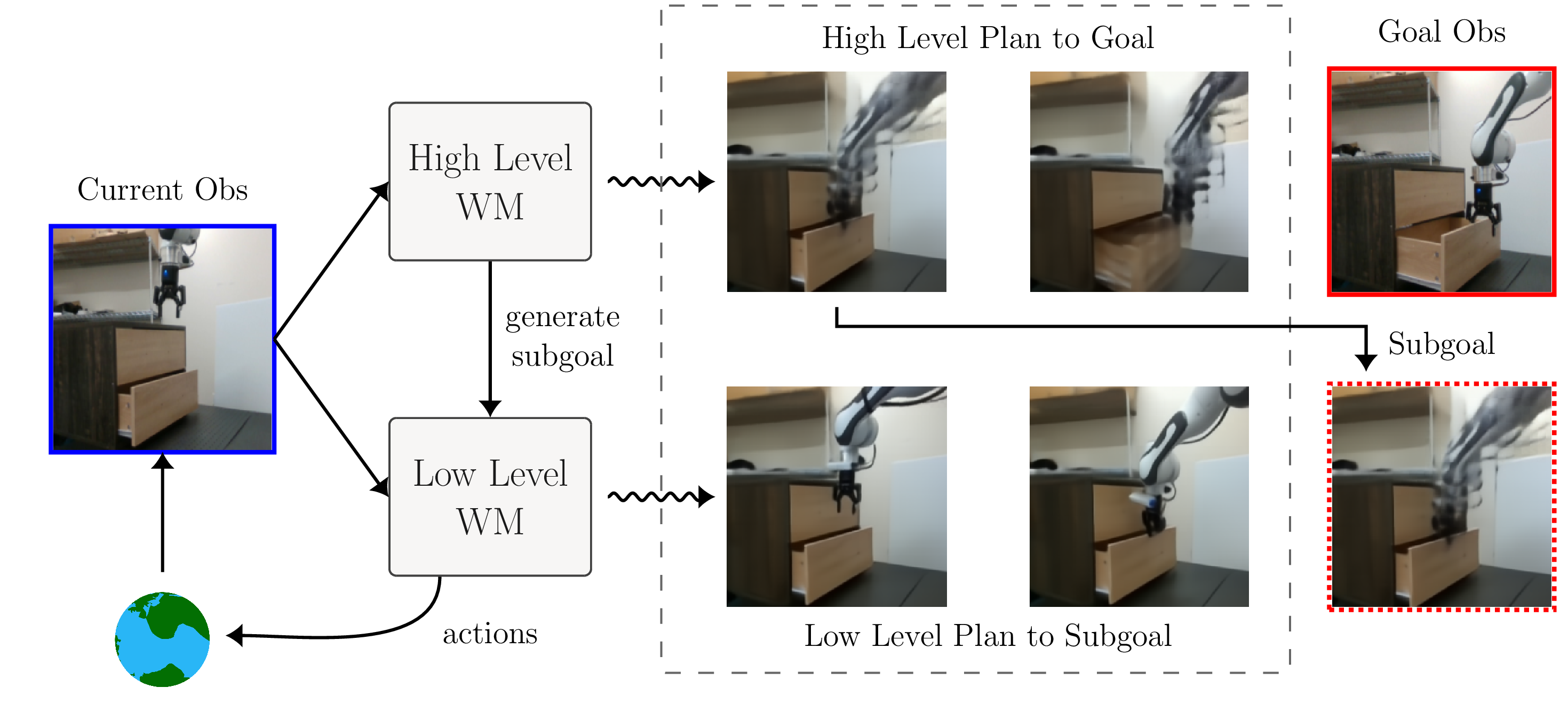
Wancong Zhang, Basile Terver, Artem Zholus, Soham Chitnis, Harsh Sutaria, Mido Assran, Amir Bar, Randall Balestriero, Adrien Bardes, Yann LeCun, Nicolas Ballas Preprint, 2025 project page / paper Hierarchical MPC in a shared latent space that enables zero-shot non-greedy planning from images. A high-level planner optimizes macro-actions using a long-horizon world model to generate subgoals, while a low-level planner executes primitive actions to reach each subgoal. Achieves 70% success on real-robot pick-and-place from a single goal image (vs. 0% for flat planners), with up to +44% absolute success rate gains and 3x lower planning cost on long-horizon tasks. Model-agnostic abstraction that consistently improves diverse latent world models (VJEPA2-AC, DINO-WM, PLDM). |
|
Depth Barrier Regularization for Collision Aware Egocentric Navigation
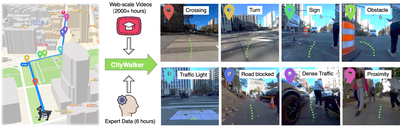
Advised by Prof. Chen Feng Graduate Research, Sep 2025 - Dec 2025 CityWalker project Building on CityWalker for collision-aware urban navigation using depth barrier regularization. Developing differentiable safety constraints from monocular depth to prevent steering into obstacles while preserving data-driven policy performance. Co-mentored by postdoc Jing Zhang and PhD candidate Xinhao Liu at AI4CE Lab. |
|
Action-Aware REPA for Diffusion Based World Models
Advised by Prof. Saining Xie Research Project, Oct 2024 Collaborators: Shaswat Patel, Soham Chitnis Developed Action-aware Representation Alignment (AC-REPA) for action-conditioned diffusion world models that simulate egocentric futures for navigation planning. Aligned internal denoising representations of Conditional Diffusion Transformers (CDiT) to frozen video foundation encoders (VideoMAE-v2) with action conditioning. Combined feature alignment with action-gated spatio-temporal relation distillation (AC-TRD) to improve temporal coherence, reduce artifacts, and enhance planning success in navigation environments. |
|
|
Attention-Aware DPO for Reducing Hallucinations in Multi-Image QA
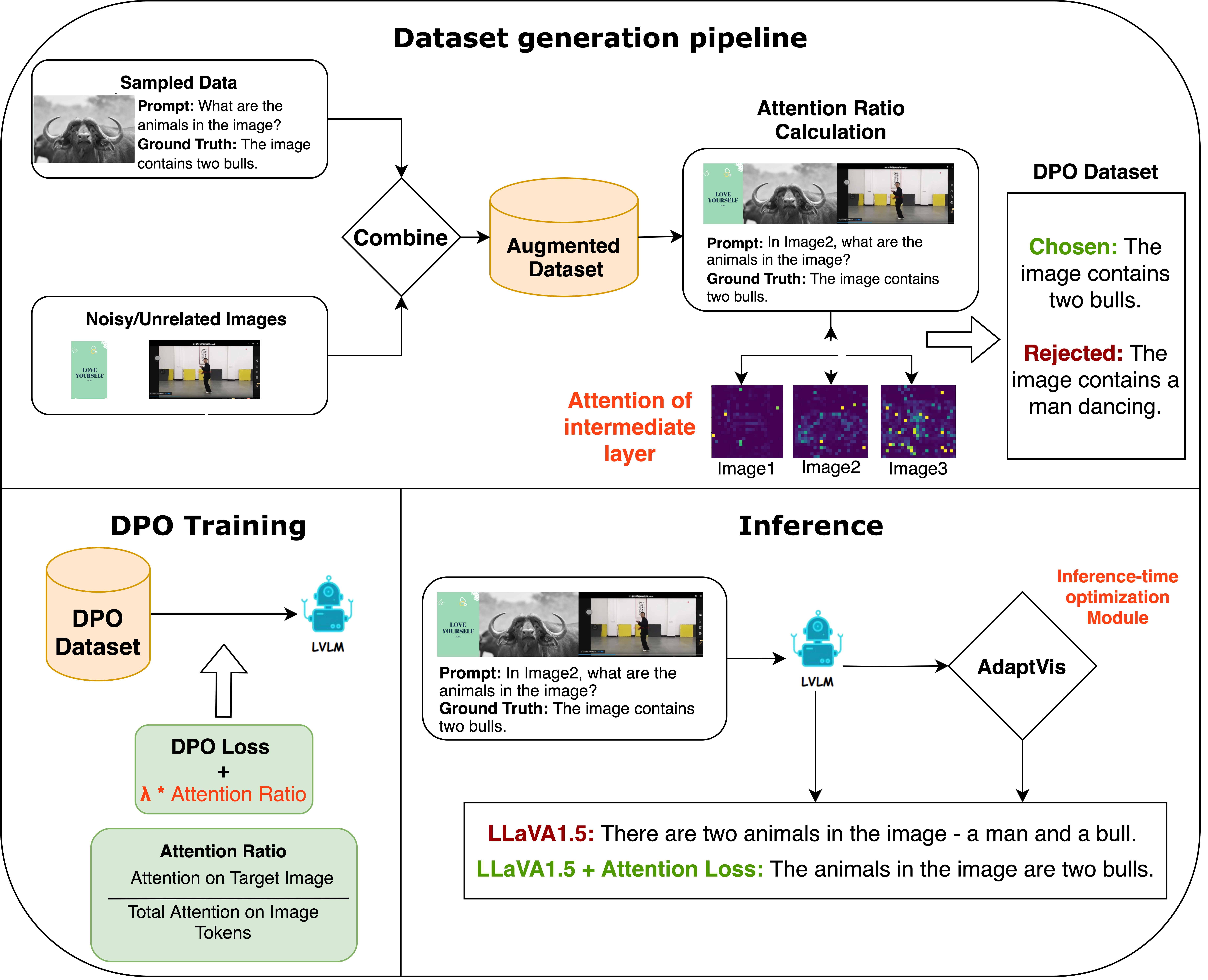
Advised by Prof. Saining Xie Research Project, Nov 2024 report Engineered DPO loss incorporating cross attention penalties to reduce hallucinations in multi image QA for Large Vision Language Models (LVLMs), improving target image focus by 33.93% (vs. 29.43% baseline). Performed inference time optimization by confidence based attention scaling, boosting accuracy by 10%. Trained on LLaVA665k augmented datasets using LoRA fine-tuning. |
ProjectsProduction AI systems deployed to solve real-world problems with measurable impact. These projects are actively used by professionals in their daily workflows, delivering significant productivity improvements and enabling new capabilities through practical applications of deep learning and computer vision. |
|
|
MLX - Active Open Source Contributor
Open Source Contribution, 2025 - Present GitHub repository Active contributor to MLX, Apple's array framework for machine learning on Apple silicon. MLX provides a NumPy-like Python API with composable function transformations, lazy computation, and unified memory model. Contributing to the development of efficient ML primitives and optimization techniques for deploying models on Apple devices, enabling researchers and developers to leverage hardware-accelerated machine learning capabilities. |
|
Generative Fashion Design Agent
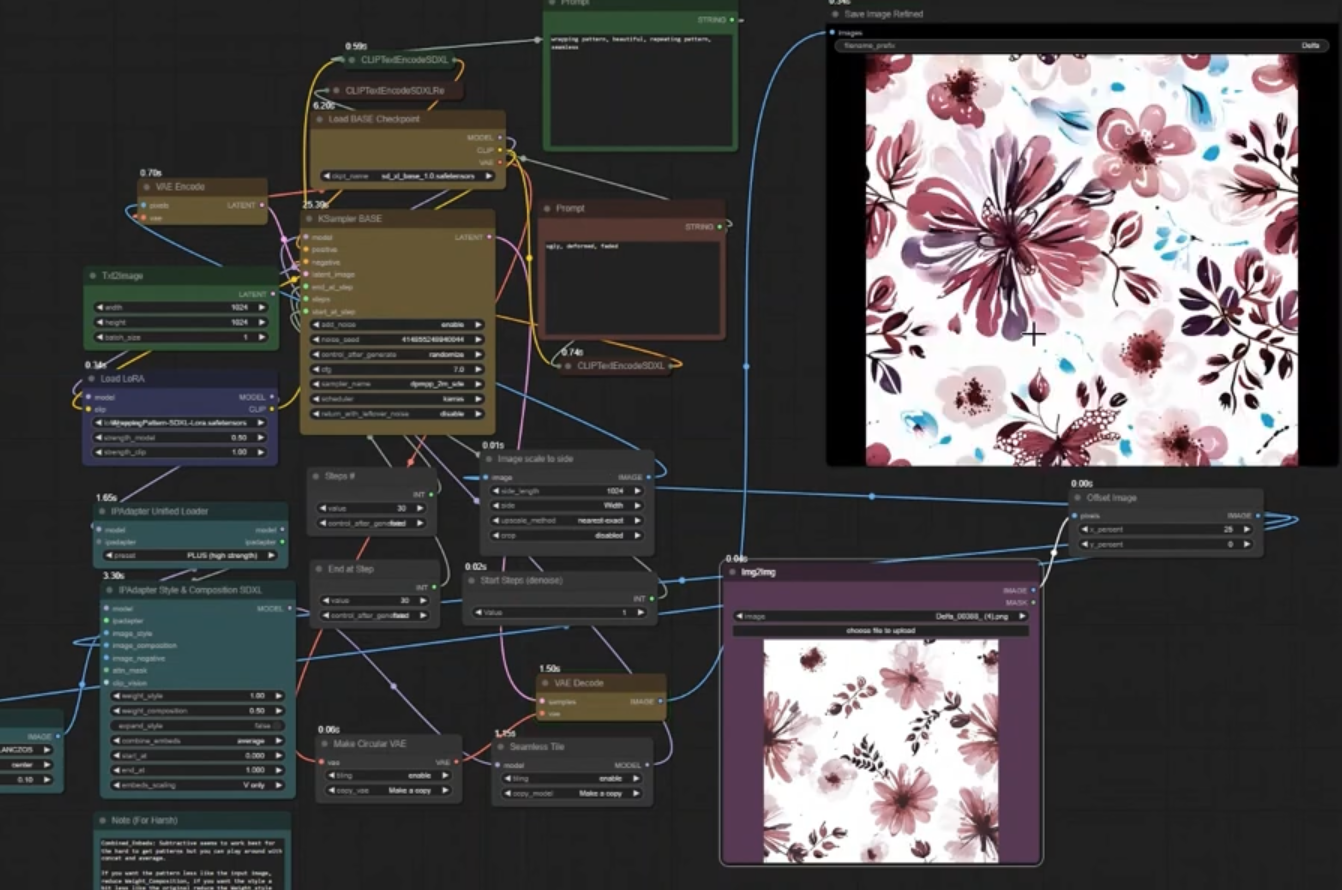
20+ daily active users (DAU), Jan 2024 demo video Developed AI-powered fashion design system by fine-tuning SDXL diffusion model using LoRA and VAE to generate textile patterns inspired from base images. Leveraged Meta's Segment Anything Model (SAM) for precise image layer extraction, enabling diverse textile patch creation. Deployed production system serving 20+ daily active users (DAU are sketch artists), boosting their productivity by over 75% at the industry level. |
Professional ExperienceMy professional experience spans research internships, industry engineering roles, and research leadership positions across diverse domains. From causal intelligence research at Causal Labs to IoT voice recognition at Whitelion, production ML systems at Jaipur Robotics, and autonomous navigation leadership at NYU. I've consistently delivered solutions that improve performance metrics and reduce manual work through AI innovation. |

|
Machine Learning Research Intern - Causal Labs
Research Internship company info |

|
Student Leader - NYU Self Drive | AI4CE Lab
Vertically Integrated Project, Sep 2024 - Present project page Led the team to develop autonomous navigation with world models as visual inertial state estimators for localization and controls. Built visual place recognition using YOLO, DINOv2 and VLAD-BuFF to improve image matching by 30%. Participated at the joint competition by NASA & Johns Hopkins University's Lunar Autonomy Challenge. |

|
Machine Learning Engineer - Jaipur Robotics Sagl
Full-time Role, Apr 2023 - Aug 2024 company info Performed image classification and segmentation by fine-tuning YOLO and CLIP for downstream tasks. Used Segment Anything and LabelStudio to create datasets resulting in reduction of human work by 60%. Created resilient backend architectures by containerizing applications with Docker and Google Cloud Platform using Flask, Streamlit, and cloud services for production ML deployments. |

|
Software Engineer Intern - Whitelion
Software Engineering Internship, May 2022 - Aug 2022 company info Designed and developed software modules for voice recognition in smart switch systems, improving recognition accuracy from 78% to 89%. Integrated NLP capabilities using spaCy to enhance user-device interaction through natural language commands. Built and optimized data processing pipelines for motion and TV sensor data using TensorFlow and scikit-learn, contributing to intelligent energy management features. Delivered robust real-time functionality in embedded environments through system integration and performance optimization. |
|
Template adapted from Jon Barron's website |